前言 这是pytorch深度学习的第二篇,第一篇为pytorch搭建CNN网络实现MNIST数据集的图像分类 pytorch自己动手搭建一个AlexNet来训练一个花分类的数据集。同时,本篇文章所有的代码都已上传github,欢迎大家star和fork。链接在此:begin-deep-learning
AlexNet简介 AlexNet是一个卷积神经网络,是2012年的ISLVRC 2012竞赛的冠军网络,由亚历克斯·克里泽夫斯基(Alex Krizhevsky)设计(这也是AlexNet名字的来源),也是自2012年以后,深度学习开始迅速发展。
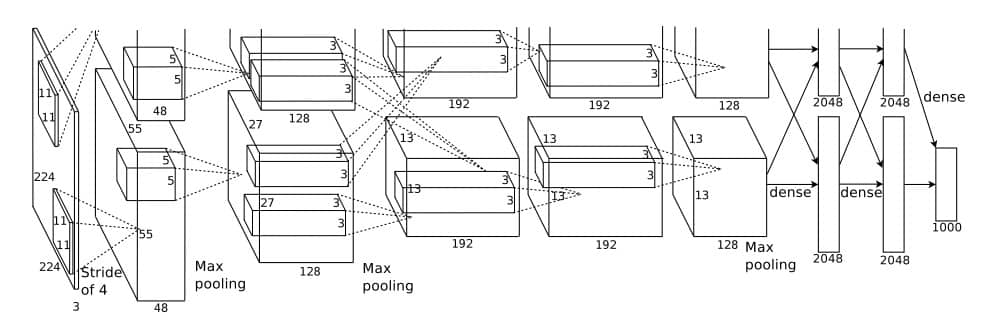
特点 由于AlexNet的计算成本很高,所以AlexNet使用了GPU来加速训练,使得计算具有可行性 使用了ReLU激活函数,而之前大多使用的是sigmoid或者tanh函数作为激活函数,所以具有更好的训练性能,能更快速地收敛 使用了LRN局部响应归一化(这个目前还不太了解) 使用dropout随机失活神经元,减少过拟合 AlexNet网络结构详解 AlexNet结构图 首先先上结构图,这是后面一系列分析的来源:
图源原论文ImageNet Classification with Deep Convolutional Neural Networks 这里可以看到图有上下两部分,这是因为作者使用了两块GPU来训练(Training on Multiple GPUs),上下地结构是一样的,所以只看下面这一部分就好了。
基本结构 从图中可以看出,该网络有5个卷积层(Conv)和三个全连接层(FC),前两个卷积层后面都跟有一个最大池化层(Max pooling),卷积层和全连接层之间也有一个池化层。接下来具体分析每一层。
Conv 1 首先,从图中可以看出,输入的是\(224\times224\times3\) 的图像,卷积核大小为11(即kernel_size=11)步长(Stride)为4,输出为\(55\times55\times48\) ,即图像高度和宽度变为了55,通道数(channel)变为了48,所以使用了48个卷积核,根据公式\(n^{[l]}=\frac{n^{[l-1]}+2p-f}{s}+1\) 可以得出2p=3,所以padding应该为(1,2),当然简单地设为2也是可以的,因为pytorch会自动舍去多余的部分,并不影响结果;所以,该层具体信息如下:
输入:input_size = [224, 224, 3] 卷积层:in_channels:3 out_channels:48 kernel_size:11 stride:4 padding:2 输出:output_size = [55, 55, 48] Maxpool 1 该层为池化层,从图中可以看出原本Height为55的图像经过池化后变成了27,可以想到kernel_size为3,步长为2,看了很多代码,事实证明也确实是这么做的。
输入:input_size = [55, 55, 48] 池化层: 输出:output_size = [27, 27, 48] Conv 2 与Conv 1 类似,通过看图和一些操作,我们可以得出我们想要的参数,下面类似,我都不再赘述,只是将参数列举出来。
输入:input_size = [27, 27, 48] 卷积层:in_channels:48 out_channels:128 kernel_size:5 stride:1 padding:2 输出:output_size = [27, 27, 128] Maxpool 2 输入:input_size = [27, 27, 128] 池化层: 输出:output_size = [13, 13, 128] Conv 3 接下来为三个连续的卷积层。
输入:input_size = [13, 13, 128] 卷积层:in_channels:128 out_channels:192 kernel_size:3 stride:1 padding:1 输出:output_size = [13, 13, 192] Conv 4 输入:input_size = [13, 13, 192] 卷积层:in_channels:192 out_channels:192 kernel_size:3 stride:1 padding:1 输出:output_size = [13, 13, 192] Conv 5 输入:input_size = [13, 13, 192] 卷积层:in_channels:192 out_channels:128 kernel_size:3 stride:1 padding:1 输出:output_size = [13, 13, 128] Maxpool 3 输入:input_size = [13, 13, 128] 池化层: 输出:output_size = [6, 6, 128] 经过第三个池化层以后,会将得到的[6, 6, 128]的tensor展开,然后与第一个全连接层相连
FC 1 、FC 2 、FC 3 由图中可以看出,输入全连接层的参数为\[128\times6\times6\] ,经过三个全连接层,最终输出为1000,实际上这个1000指的是分的类别数,即num_classes,所以三个全连接层的变换如下:
\[Maxpool3 \rightarrow 128\times6\times6 \rightarrow FC 1 \rightarrow 2048 \rightarrow FC 2 \rightarrow 2048 \rightarrow FC 3 \rightarrow 1000(num\_classes)\]
代码实例分析 数据集准备 下载 首先到如下网址下载数据集:
http://download.tensorflow.org/example_images/flower_photos.tgz
此数据集包含 5 中类型的花(雏菊daisy,蒲公英dandelion,玫瑰roses,向日葵sunflower,郁金香tulips),每种类型有600~900张图像不等。
训练集和测试集划分 首先新建flower_data文件夹,将下载的数据集移入flower_data文件夹下,然后解压数据集,之后回到上一层目录(即flower_data同级目录)新建一个.py文件用来写入脚本划分数据集,名称随意,例如我用的是split_data.py,打开该文件,写入如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import osfrom shutil import copyimport randomdef mkfile (file ): if not os.path.exists(file): os.makedirs(file) file = 'flower_data/flower_photos' flower_class = [cla for cla in os.listdir(file) if ".txt" not in cla] mkfile('flower_data/train' ) for cla in flower_class: mkfile('flower_data/train/' +cla) mkfile('flower_data/val' ) for cla in flower_class: mkfile('flower_data/val/' +cla) split_rate = 0.1 for cla in flower_class: cla_path = file + '/' + cla + '/' images = os.listdir(cla_path) num = len (images) eval_index = random.sample(images, k=int (num*split_rate)) for index, image in enumerate (images): if image in eval_index: image_path = cla_path + image new_path = 'flower_data/val/' + cla copy(image_path, new_path) else : image_path = cla_path + image new_path = 'flower_data/train/' + cla copy(image_path, new_path) print ("\r[{}] processing [{}/{}]" .format (cla, index+1 , num), end="" ) print () print ("processing done!" )
此脚本将数据集按9:1的比例划分为训练集train和验证集val,然后运行该脚本进行划分。
最终得到的目录结构大致如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |-- flower_data |-- flower_photos |-- daisy |-- dandelion |-- roses |-- sunflowers |-- tulips |-- LICENSE.txt |-- train |-- daisy |-- dandelion |-- roses |-- sunflowers |-- tulips |-- val |-- daisy |-- dandelion |-- roses |-- sunflowers |-- tulips |-- flower_photos.tgz |-- split_data.py
具体代码 module.py 首先为模型定义部分module.py,该部分定义了我们的网络结构AlexNet,即上面详解的部分,所以只需要将上面详解的部分转换为pytorch代码即可,比较简单,每一步pytorch都有专门的函数,所以调包就完事了。下面是具体代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import torchfrom torch import nnclass AlexNet (nn.Module ): def __init__ (self, num_classes = 1000 ): super (AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3 , 48 , kernel_size=11 , stride=4 , padding=2 ), nn.ReLU(inplace=True ), nn.MaxPool2d(kernel_size=3 , stride=2 ), nn.Conv2d(48 , 128 , kernel_size=5 , stride=1 , padding=2 ), nn.ReLU(True ), nn.MaxPool2d(kernel_size=3 , stride=2 ), nn.Conv2d(128 , 192 , kernel_size=3 , stride=1 , padding=1 ), nn.ReLU(True ), nn.Conv2d(192 , 192 , kernel_size=3 , padding=1 ), nn.ReLU(True ), nn.Conv2d(192 , 128 , kernel_size=3 , padding=1 ), nn.ReLU(True ), nn.MaxPool2d(kernel_size=3 , stride=2 ), ) self.classifier = nn.Sequential( nn.Dropout(p=0.5 ), nn.Linear(128 *6 *6 , 2048 ), nn.ReLU(True ), nn.Dropout(p=0.5 ), nn.Linear(2048 ,2048 ), nn.ReLU(True ), nn.Linear(2048 , num_classes), ) def forward (self, x ): x = self.features(x) x = torch.flatten(x, start_dim=1 ) x = self.classifier(x) return x
train.py train.py为训练部分的代码,主要是加载和处理数据集,调用刚刚定义的模型进行训练,以及打印训练过程中的信息,使训练过程可视化。这里直接上代码,具体的解释都在注释里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import torchimport torchvisionfrom torchvision import transforms, datasets, utilsimport matplotlib.pyplot as pltimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom module import AlexNetimport jsonimport osimport timeDEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) BATCH_SIZE = 32 EPOCH = 10 LR = 0.0002 print (DEVICE)data_transform = { "train" : transforms.Compose([transforms.RandomResizedCrop(224 ), transforms.RandomHorizontalFlip(p=0.5 ), transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 ))]), "val" : transforms.Compose([transforms.Resize((224 , 224 )), transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 ))])} data_root = os.path.abspath(os.path.join(os.getcwd(),".." )) image_path = data_root + "/data_set/flower_data/" train_dataset = datasets.ImageFolder(root=image_path + "/train" , transform=data_transform["train" ]) train_num = len (train_dataset) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True , num_workers=0 ) validate_dataset = datasets.ImageFolder(root=image_path + "/val" , transform=data_transform["val" ]) val_num = len (validate_dataset) validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=BATCH_SIZE, shuffle=True , num_workers=0 ) flower_list = train_dataset.class_to_idx cla_dict = dict ((val, key) for key, val in flower_list.items()) json_str = json.dumps(cla_dict, indent=4 ) with open ('class_indices.json' , 'w' ) as json_file: json_file.write(json_str) net = AlexNet(num_classes=5 ) net.to(DEVICE) loss_function = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=LR) save_path = './AlexNet.pth' best_acc = 0.0 train_counter = [] train_losses = [] for epoch in range (EPOCH): net.train() running_loss = 0.0 time_start = time.perf_counter() for step, data in enumerate (train_loader, start=0 ): images, labels = data optimizer.zero_grad() outputs = net(images.to(DEVICE)) loss = loss_function(outputs, labels.to(DEVICE)) loss.backward() optimizer.step() running_loss += loss.item() train_losses.append(loss.item()) train_counter.append((step*BATCH_SIZE) + ((epoch-1 )*len (train_loader.dataset))) rate = (step + 1 ) / len (train_loader) a = "*" * int (rate * 50 ) b = "." * int ((1 - rate) * 50 ) print ("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}" .format (int (rate * 100 ), a, b, loss), end="" ) print () print ('%f s' % (time.perf_counter()-time_start)) net.eval () acc = 0.0 with torch.no_grad(): for val_data in validate_loader: val_images, val_labels = val_data outputs = net(val_images.to(DEVICE)) predict_y = torch.max (outputs, dim=1 )[1 ] acc += (predict_y == val_labels.to(DEVICE)).sum ().item() val_accurate = acc/val_num if val_accurate > best_acc: best_acc = val_accurate torch.save(net.state_dict(), save_path) print ('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' % (epoch + 1 , running_loss / step, val_accurate)) print ('Finished Training' )fig = plt.figure() plt.plot(train_counter, train_losses, color='blue' ) plt.legend('Train Loss' , loc='upper right' ) plt.xlabel('number of training examples' ) plt.ylabel('loss' ) plt.show()
predict.py 该部分主要检验刚刚的训练成果,通过调用我们刚刚训练好的神经网络,对我们从网上随意下载的一张图片进行分类,并且给出对应的可能性,可以随意从网上下载一张五种花的图片,然后丢入模型进行预测就好了。具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import torchfrom module import AlexNetfrom PIL import Imagefrom torchvision import transformsimport matplotlib.pyplot as pltimport jsondata_transform = transforms.Compose( [transforms.Resize((224 , 224 )), transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 ))]) images = ["tulips" , "dandelion" , "roses" , "sunflower" , "daisy" ] for i in images: img = Image.open ("predict/" +i+".jpg" ) plt.imshow(img) img = data_transform(img) img = torch.unsqueeze(img, dim=0 ) try : json_file = open ('./class_indices.json' , 'r' ) class_indict = json.load(json_file) except Exception as e: print (e) exit(-1 ) model = AlexNet(num_classes=5 ) model_weight_path = "./AlexNet.pth" model.load_state_dict(torch.load(model_weight_path)) model.eval () with torch.no_grad(): output = torch.squeeze(model(img)) predict = torch.softmax(output, dim=0 ) predict_cla = torch.argmax(predict).numpy() print ("origin: " +i+"\tpredict: " +class_indict[str (predict_cla)], "\tProbability: " ,predict[predict_cla].item())
结果展示 训练过程展示
可以看出,十个epoch已经可以训练出准确率高达70%的模型了,效果还是比较理想的。
预测结果展示 我从Google上随意找了五类图片各一张,然后丢入模型进行预测,最终预测得到的结果如下:
可以看出,所有图片均预测正确,而且可能性大多比较高,所以还是比较理想的。
结语 至此,关于AlexNet的模型介绍详解和具体的图像分类都已经做完,这个过程中,我曾经尝试改变模型,使全连接层更加平缓地输出五个类别,而不是从2048直接变为5,但是发现准确率反而降低了,事实证明,还是原模型更好。另外,调参确实浪费时间且折磨人,但是看着模型一点点变好,训练出来的准确率一点点提高的喜悦和成就感也是无与伦比的,这玩意确实吸引人。接下来会研究另外一个深度学习的经典模型VGG,并做一些实际的应用,慢慢来吧,先打好基础,才能走得更稳,更远。